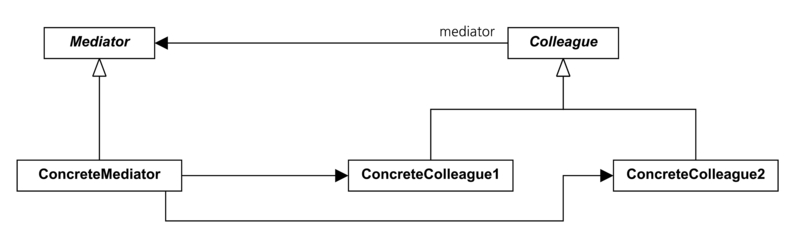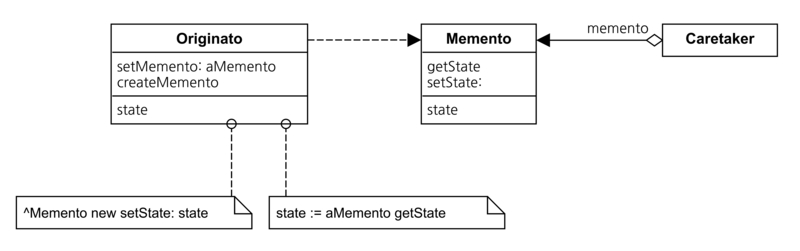
Memento패턴은 기록에 대한 패턴이다. 기록이 필요한 이유는 무엇일까? 기록을 참고해야할 무언가가 있기 때문이다. 기록이 존재함으로서 과거의 이력을 살펴보고, 그 결과로 무언가 다른 행동을 할 수도 있다. 이 경우 다른 행동은 redo/undo 가 될 것이다.
여기서 잠시 객체지향의 3대 요소를 생각해보자. 그렇다! 상속성, 캡슐화, 다형성이다. Memento 패턴이 존재하는 이유를 생각해보자. 객체의 기본은 자신의 내부상태를 외부에 드러내지 않고 동작하는 것에 있다. redo/undo 를 위해 자신의 상태를 필요할 때 마다 외부에서 접근 가능하게 드러내는 것은 캡슐화의 원칙에 위배된다. 이런 필요 덕분에 Memento패턴이 구상되었다. 객체가 필요할 때 자신의 상태를 저장하는 “자신 전용의 별도 창고”에 보관하고, 외부에서의 요청이 있을 때 스스로가 창고에 접근해서 필요한 정보를 용도에 맞게 사용하면 된다.
originator의 Memento class 는 내부적으로 command 패턴 (status의 히스토리 목록을 유지)을 구현하고, 어플리케이션 전첵적으로 command 패턴을 사용하여 이 전체적 패턴에 Originator에 대한 히스토리를 남겨서 관리하면 서로의 간섭이 적은 redo/undo를 구현 할 수 있다. originator의 memento인스턴스 내부에서는 데이터를 collection으로 관리한다고 했을 때, originator의 클라이언트는 memento의 인스턴스를 인식할 수 없기 때문에 캡슐화가 위배되는 경우를 비껴가는데도 유용하다.