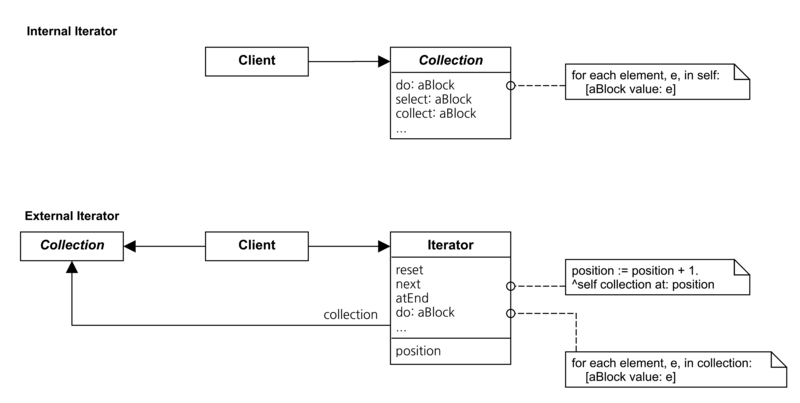
Iterator패턴에 대해서는 여러가지 설명이 있지만 가볍게 보면 Proxy패턴과 비슷해 보이기도 한다. 뒤쪽에 있는 객체를 감추고 접근권한을 통제 한다는 점에서는 충분히 비슷할 수 있다. 하지만 Iterator패턴의 목적을 명확하게 생각해 볼 필요가 있다. 이 패턴은 자로(데이터)의 제어에 그 목적이 있다. 그것도 자료 객체에 자료를 추가하거나 식제하는 등 자료 자체에 무언가 가공을 하는것이 목적이 아니라 자료의 검색에 대한 인터페이스를 제공하고 그 결과를 공급하는것이 패턴의 목적이다. 좀 더 진지하게 고민해본다면, 자료의 제어와 자료의 제공을 분리해서 자료를 다루는 코드를 개념적으로 나누어 코드관리의 효율성과 확장성을 얻을 수 있게 된다.
하나의 자료구조체에 대해 여러개의 Iterator 클래스를 붙인다면, 원하는 알고리즘으로 자료를 다루는 여러가지 방법을 확보하고, 때에 따라 추가할 수 도 있게 된다. 이 패턴은 데이터의 검색에 대한 알고리즘이 어디에 구현되는지에 따라 분류명이 달라지기도 한다. 알고리즘이 데이터클래스에 위치한다면 Iterator 클래스는 데이터의 탐색만 담당하게 되는데 이런경우를 Cursor라고 한다. 여기서 주의깊게 봐야할 부분은 바로 Cursor라고 불리는 이유이다. Cursor 클래스의 인스턴스를 통해 데이터의 탐색을 하는 경우, 이 인스턴스는 Corrent index 값을 가지게 되는데 이런 특성을 이용하면 여러개의 Cursor 인스턴스가 하나의 원본 데이터에 대한 각기 다른 탐색을 진행할 수 있다.
Iterator패턴은 그 특성상 Iterator클래스가 참조하게 되는 데이터 클래스의 자료구조에 대한 특성에 따라 영향을 받게 되는데, 이런 Iterator패턴의 특수성 때문에 Iterator 클래스의 인스턴스는 원본 데이터의 인스턴스와 생성, 제거를 함께 관리하는 “관리용 클래스”에서 취급되는것이 좋으며, 이렇게 관리 클래스를 별도로 작업하는 경우라면 Proxy 패턴으로 구조를 작업해서 데이터 인스턴스를 참조하는 Iterator 인스턴스에 대한 reference counter를 관리해 주는것이 좋다.