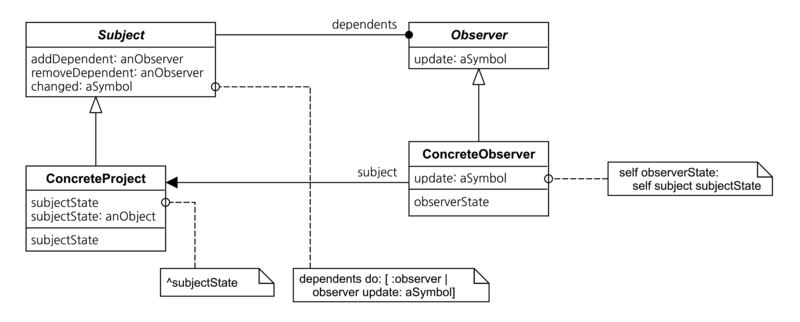
모든것이 객체(클래스)로 이루어져있는 Smalltalk 같은 시스템이나 객체지향 언어로 만들어진 어플리케이션은, 그 내부에 수많은 객체를 가지고 있게 된다. 당연히 물리적으로 보자면 바이너리(이진) 데이터의 나열에 지나지 않기 때문에 비-객체지향 언어로 만들어진 어플리케이션과 본질적인 차이는 없지만, 여기서는 논리적인 구조를 다루고 있으니 그 점은 넘어가도록 하자. 여튼 이렇게 수많은 객체사이에 특정 객체를 바라보는 객체를 B라고 하고 특정 객체를 A라고 가정하자. A의 내부에서 변수의 내용이 갱신되었을 때 이 내용을 B에게 알려줘야 하는 경우가 되었다면 어떻게 해야할까? 그리고 이 B가 한개가 아니라 복수로 존재한다면 A는 어떻게 해야할까? observer패턴은 이런 경우를 풀어내기 위해 고안된 방법이다.
객체지향은 사람의 생각을 기본 모델로 해서, 생각에서 이루어지는 관계를 체계적이고 효율적으로 정리해서 구현 및 적용한 방법이다. 그렇기 때문에 이 패턴 역시 사람과의 관계에 비추어서 생각 해 보면 조금 이해하기 쉬울것이다. 나는 무언가를 가지고 관리하는 사람이고, 이런 나와 관련된 업무를 하는 다른사람이 여럿 있다고 가정하자. 이 때 다른 사람들은 내 무언가의 상태가 변화될 때 영향을 받는 업무라고 할 때 어떻게 해야 효율적일까.
당연히 나는 무언가의 상태를 관리하며 다른 사람에게 상태의 변화를 통지해주는게 가장 효율적인 방법이 될 것이다. 이 때의 나를 subject라고 하고 다른 사람을 observer라고 이해하면 된다.
observer패턴의 진행을 간단하게 보면 다음과 같다.
1. data 객체가 자신을 창조하는 객체들에게 notification을 보내서 자신의 상태변경을 알린다.
2. notification을 받은 객체는 data 객체내에서 갱신된 자료를 가져온다.
이 때 data객체가 자신을 참조하는 객체의 목록을 관리한다는 점에서는 proxy 패턴의 reference counter와 통하는 부분도 있다.
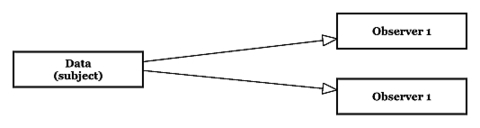
data객체를 참조하는 참조객체의 수가 1 이상일 때 data 객체에 최초의 데이터 요청이 오면 data객체 내에서 데이터를 캐싱해서 관리하고, 참조객체의 수가 0이면 data와 DB의 연결을 끊어서 리소스의 낭비를 줄일 수도 있다.