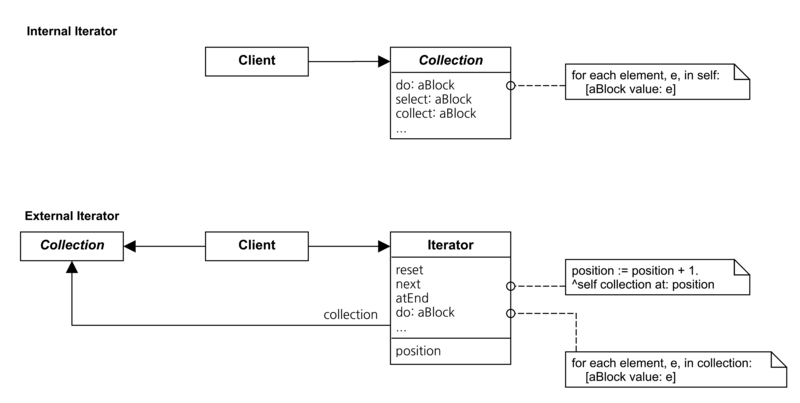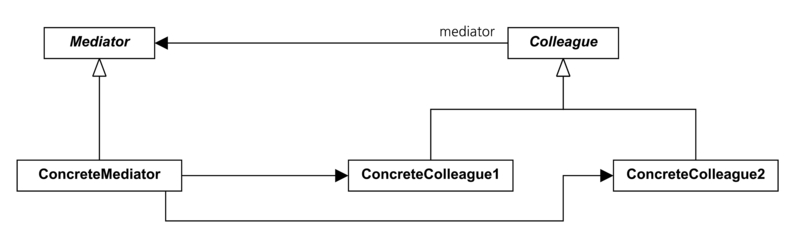
Mediator패턴은 클래스의 구조에 대한 패턴이라기 보다는 프로그램 내에서 이루어지는 작업의 구조에 대한 패턴이라는게 좀 더 명확한 설명이 될 것이다. 대부분의 패턴이 클래스의 배치와 인터페이스에 대한 문제를 중요하게 다룬다면 Mediator패턴은 객체들 사이의 관계와 작업을 유발시키고, 인스턴스들을 제어하는 방법에 초점이 밪추어져 있다는 것을 유념해야 한다.
다루어야 하는 클래스 (또는 인스턴스)가 여러개가 있고, 이것들이 서로 직접적인 상관관계는 없지만, 프로그램 내에서 필요에 따라 느슨한 결합관계를 가지고 어떠한 이벤트에 여러개의 객체가 반응해야 할 때, 이렇게 여러개의 객체를 매번 일일히(개별로)제어한다는 것은 매우 번거로운 작업이 된다. 이런경우 Business Logic에 따라 일련의 규칙을 가지고 있는 클래스를 만들어서, 이렇게 만들어진 클래스로 하여금 규칙에 따라 필요한 다수의 객체를 제어한다면 편하지 않겠는가? 이 개념을 패턴으로 정리하면 Mediator패턴이 된다.
요즘 대부분의 RDBMS 엔진을 보면 Trigger 개념을 지원하고 있다. Database 내의 특정 table 에 대해 특정 transaction을 조건으로 trigger를 걸어서, 해당 table에 이벤트가 발생되었을 때 부수적인 작업이 진행되도록 설정할 수 있다. 이렇게 작업을 미리 준비 해 놓으면 작업자는 추가적인 고민없이 table에 대한 테이터 질의작업을 진행하면, 필요한 추가작업은 자동으로 미리 준비해놓은 규칙에 따라 순서대로 진행 될 것이다. 일종의 Mediator패턴의 개념으로 동작하는 사례라고 볼 수 있지 않을까?
앞엣 설명한대로 Mediator패턴은, 퍼사드의 인터페이스를 정의하거나 규제하기위한 패턴은 아니다. Mediator클래스의 인터페이스는 작업자가 필요한대로 결정하면 된다. 단 Mediator클래스의 관리를 받아야 하는 상황의 종류가 많아진다면 상황별로 Mediator클래스를 여러개 만들어야 할 필요가 있을텐데(물론 하나의 Mediator에 메서드를 늘여서 해결할 수 있다) 이런 경우라면 라이브러리 내에서 공통으로 사용할만한 메서드 인터페이스를 Mediator추상클래스로 정의하고, Mediator하위클래스에서는 상황별로 구체적인 작업을 구현하는것도 좋은 방법이다.