패턴을 알아보면서 대부분의 내용은 [디자인 패턴]을 참고하고 있지만 Visitor 패턴만큼은 [디자인 패턴]의 내용을 가능하면 적게 참고하기 바란다. 다만 참고해야 할 키워드가 있다면 “이중 디스패치”일 것이다.
객체지향 3원칙중에 “캡슐화”가 있다. 캡슐화는 객체(또는 클래스) 내부의 데이터에 대한 보호를 지원함으로서 내부구조를 외부로 노출시키지 않는 규칙이다. 하지만 필요에 의해서 이 원칙이 깨져야 한다면 어떨까? 하나의 시나리오를 가정해보자.
1. 필요에 의해 한개의 데이터 클래스를 설계한다.
2. 외부에 제공하기 위해 데이터 클래스의 연산(←메서드)을 추가한다.
3. 또 다른 필요에 의해 데이터 클래스에 다른 연산을 추가한다.
이 경우 3번 항목의 과정을 반복하게 되면 클래스의 메서드는 계속 증가하게 된다. 클래스 내부에서 코드는 스파게티처럼 꼬이게 되며 확장등을 위한 관리가 힘들어질 수도 있다. 게다가 추가되는 연산이 다른곳(객체)에도 쓰여야 할 필요성이 생긴다면 그 때 마다 코드를 복사해서 사용 할 것인가? 이건 그다지 효율적인 유지관리 방법은 아닐것이다.
이제부터 방법을 생각해보자.
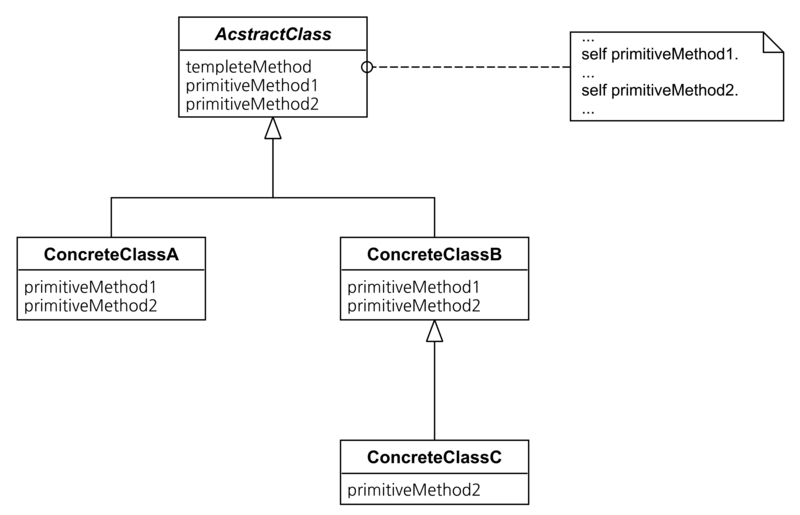
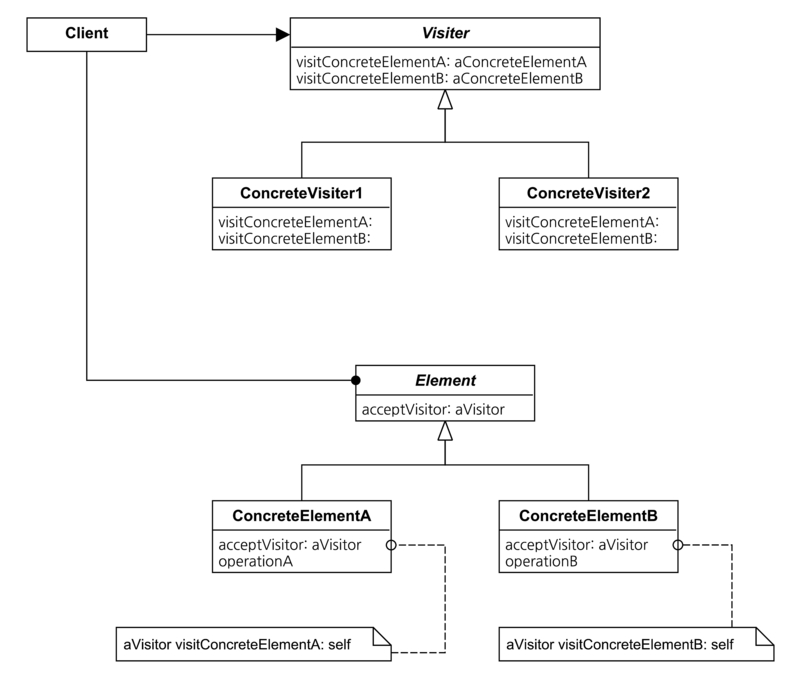
데이터를 “가공”하는 연산을 추려서 또 다른 클래스로 분리한 다음에 정리해보자. 이렇게 정리된 클래스가 여러개가 된다면 연산의 종류 자체에서도 공통점이 발견 될 것이다. 그렇다면 발견 된 공통점의 인터페이스만 추려서 추상클래스로 만들고, 연산을 적용해야 할 타입별로 하위클래스를 만들어서 연산의 구체적 내용을 구현하면 하나의 클래스군이 만들어 질 것이다. 이것이 Visitor 패턴이다.
한가지 정말 주의해야할 것이 있다. Visitor 패턴군에는 “알고리즘” 만 존재한다. 실제 데이터는 데이터를 보관하고 있는 별도의 객체에 있을것이다. Visitor객체(클래스)에게 데이터객체가 보관하고 있는 데이터로의 접근경로를 열어주는 순간에 캡슐화는 위배된다. 연산의 재사용과 관리에 중점을 둔다면 Visitor 패턴의 사용이 적절하겠지만, 적용에는 충분한 주의가 뒤따라야 한다는 사실을 염두에 두어야 한다.