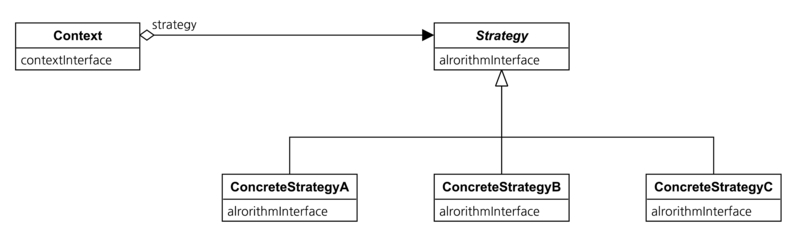
Strategy는 사용자가 라이브러리를 구축할 때 사용하는 일반적 개념과 가장 근접된 패턴이다. Sort(정렬) 알고리즘에는 여러가지가 있다. 수학적, 또는 논리적 차이를 가지는 이 알고리즘에는 대표적으로 Bubble, Quick 등이 있다. 이 알고리즘들을 상황에 맞게 사용할 수 있도록 정리해두고 싶다면 어떤 방법이 가장 좋을까? 이럴때 사용하는 것이 바로 Strategy 패턴이다.
Strategy패턴을 구성하고 싶을 때에는 먼저 대상들에게서 공통분모를 추출해서 추상클래스를 만드는 작업부터 시작하는것이 좋다. Sort 알고리즘은 원본 데이터를 받아 내부에서 정렬을 진행한 후 정렬된 결과를 반환한다. 이렇게 원본 데이터를 받아야 하는 인터페이스를 추상클래스에서 정의한 후 하위클래스에서 실제 동작할 내용을 구현하면 된다. 이렇게 하면 알고리즘을 사용해야 하는 context는 스스로가 원하는 알고리즘을 동일한 인터페이스로 골라서 쓰기만 하면 된다.
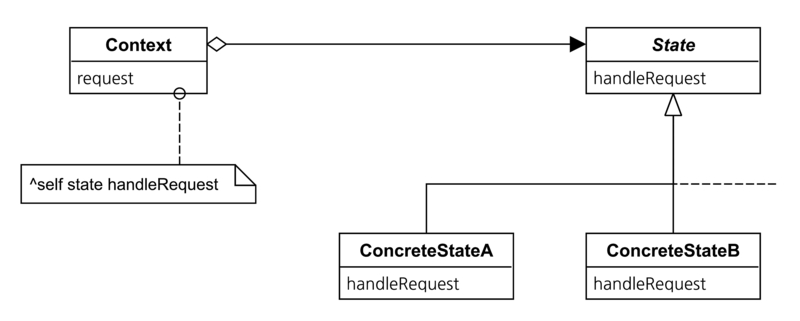
Strategy패턴은 그 구조상 State패턴과 유사성을 지닌다. 그렇다면 두 패턴은 어떤 차이가 있을까?
State패턴에서는 State의 하위클래스를 타입으로 취급하고 사용하게 권장한다. 반면 Strategy는 하위클래스를 연산으로 취급한다. Strategy패턴에서는 하위클래스의 추가가 타입의 증가로 취급되는것이 아니라 연산의 종류가 늘어나는 것으로 취급 될 것이다. 그리고 State는 context에서 state의 하위클래스가 가지고 있는 내부구현을 자세히 알지 않아도 반환값만 처리하면 되지만, Strategy는 context에서 Strategy의 하위클래스에 들어있는 내부구현 내용을 가능한 만큼 정확하게 숙지해야한다. 또한 context에서 관리 객체 변수가 참조하는 인스턴스가 상태에 따라 바뀐다면 State 패턴, 필요에 따라 지정해서 사용한다면 Strategy패턴으로 분류할 수 있다.